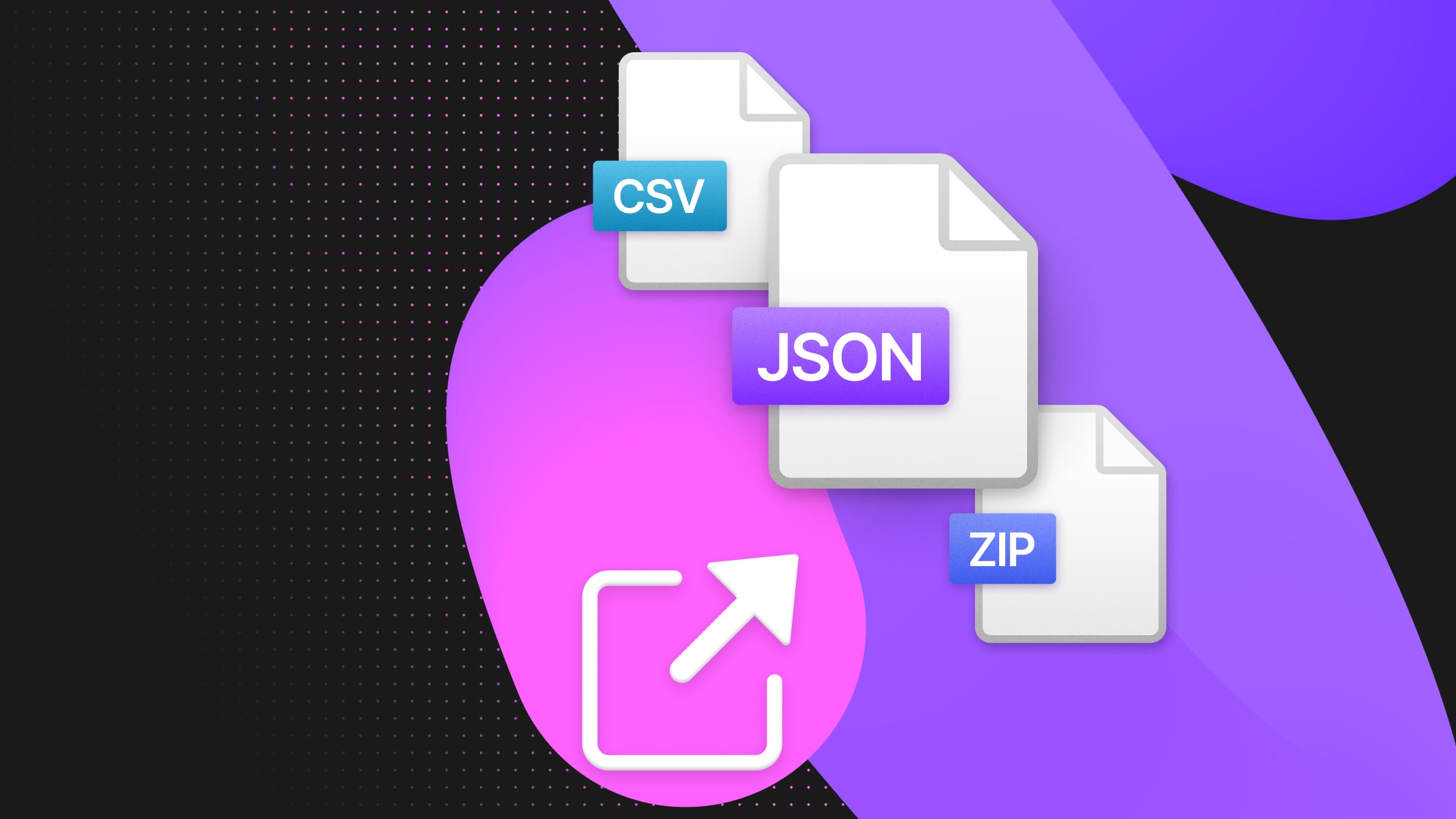
Export to CSV, JSON and XLSX from the Neon console
New features, and new open-source libraries to power them
After spending a bit of time with Neon’s SQL Editor making \d and friends work, there were a couple of other things I wanted to bring to it, both related to the query results.
The first was a simple expand-to-window control for the results pane, to get a better and less cramped look at query result tables and (especially) the graphical EXPLAIN output produced by PEV2. You can now find such a button at the bottom right of the SQL Editor any time there are query result on-screen.
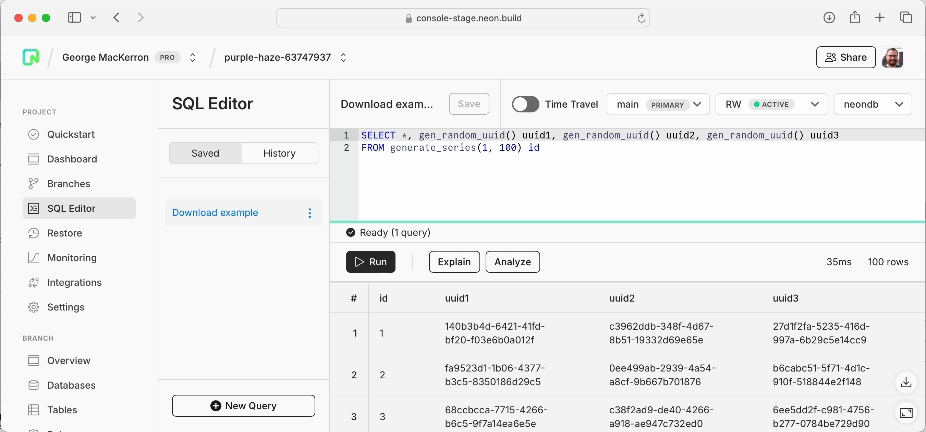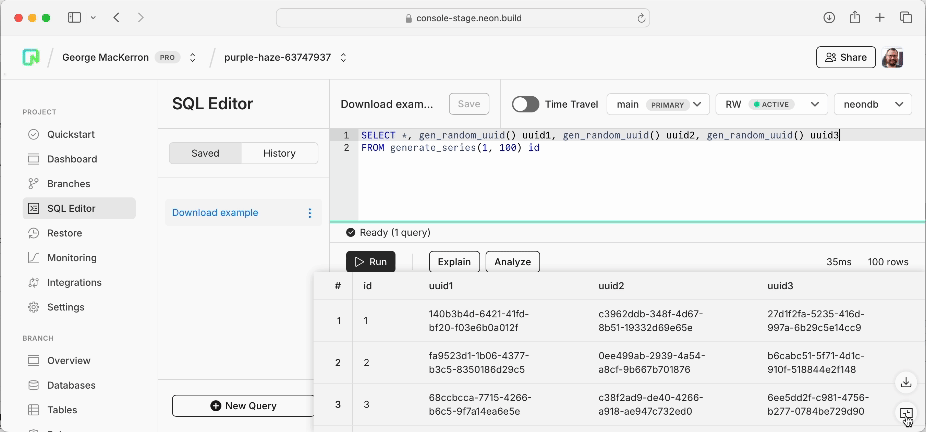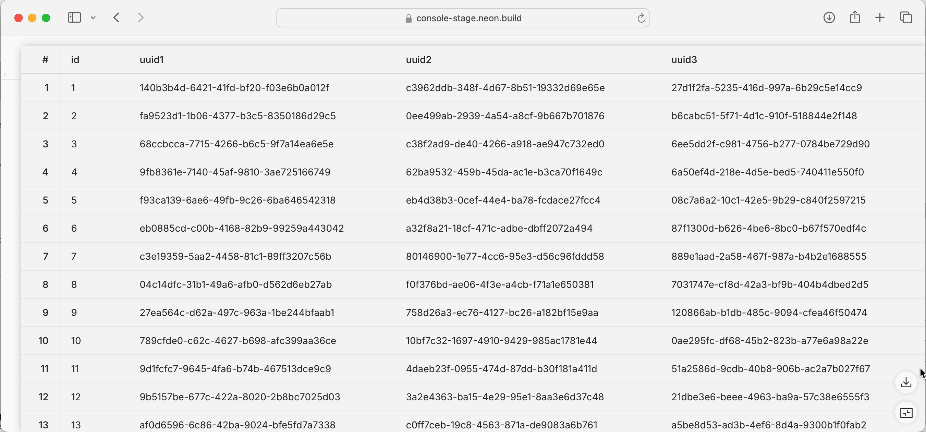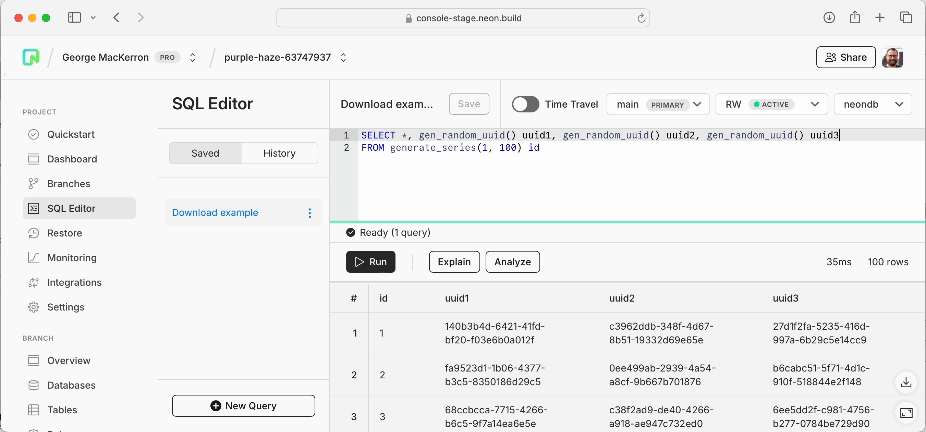
The second was that I wanted to be able to download tables of results. One time, I ran a query in the SQL Editor, hoping to produce a simple chart of what came back, and was disappointed to find that my best next step was actually to open Terminal and connect via psql to re-run the same SQL using \COPY (...) TO '/path/to.csv' CSV HEADER. I wanted to fix that.
But what download formats should be provided?
- CSV is an obvious choice:
psqlalready offers it, almost any tool (Excel, Numbers, R, Stata, etc.) can import it, and it’s not too hard to generate by following RFC4180 or the W3C’s best practice recommendations. - A colleague suggested JSON, which is another widely-supported interchange format, and an easy way to ingest data from your programming language of choice.
- Finally, I thought it would be nice to offer a native Excel (.xlsx) file on top.
On that last point, my colleagues were not immediately convinced: Why bother, when Excel reads CSV?
Well, when I download a CSV file for Excel, there’s a bunch of steps that always come next, and I find these get old pretty quickly. First, I drag the file to Excel (I can’t just open the file from Downloads, since CSV is associated with Numbers by default on Mac). Second, I bold, freeze, and auto-filter the headings. Next, I fix the column widths. Then, I make sure dates and times are sensibly represented. Finally, I save to a native Excel file. Wouldn’t it be delightful, I thought, if all that work could be automated away?
Long story short, all three formats — CSV, JSON, and XSLX — can now be exported from the SQL Editor. The icon is at bottom right, just above the new expand-to-window control, any time that you’re looking at a query result table. It’s all done client-side, in JavaScript, using the query results the browser already has.
So for results like this:
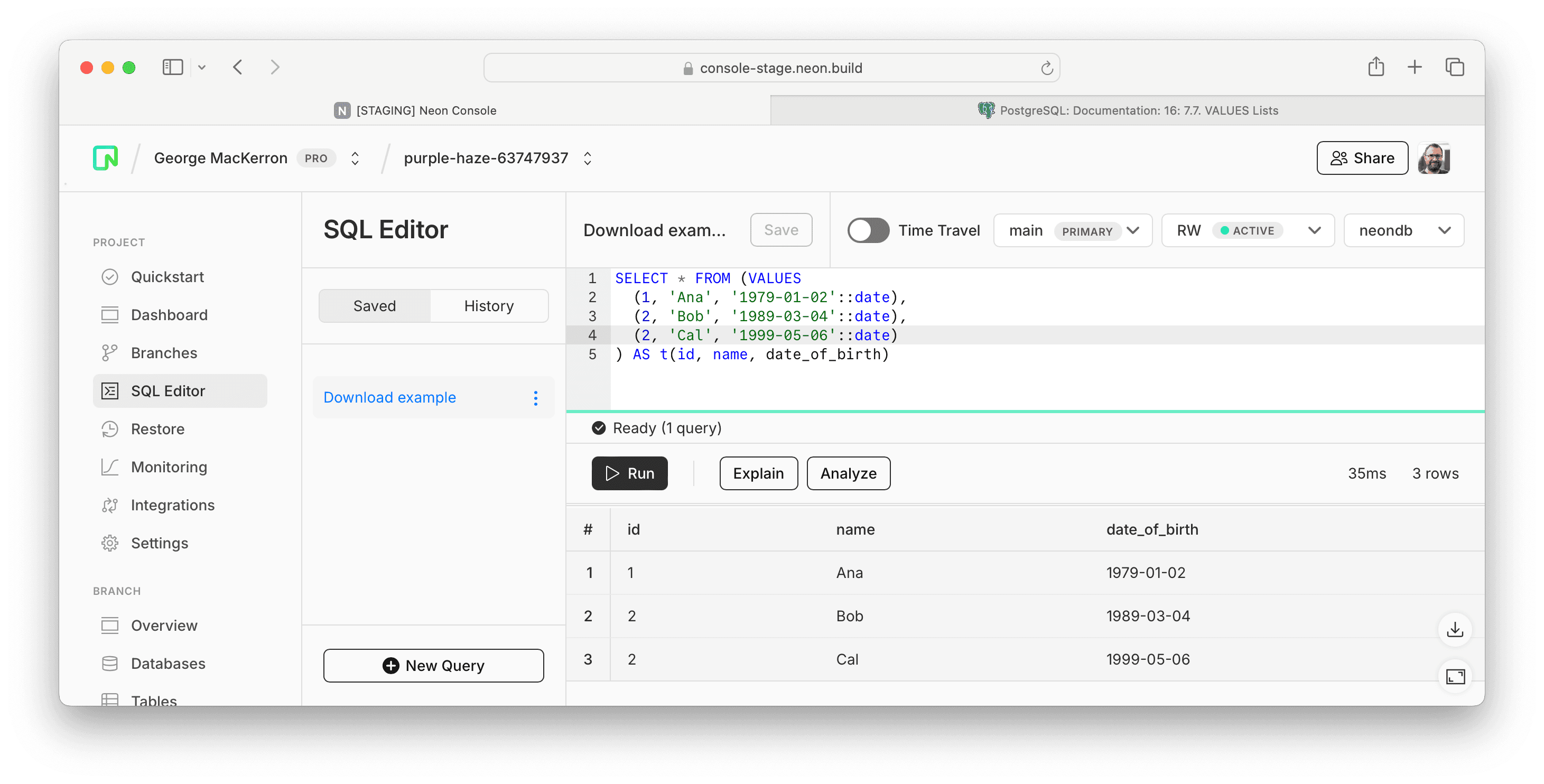
You get downloads like this:
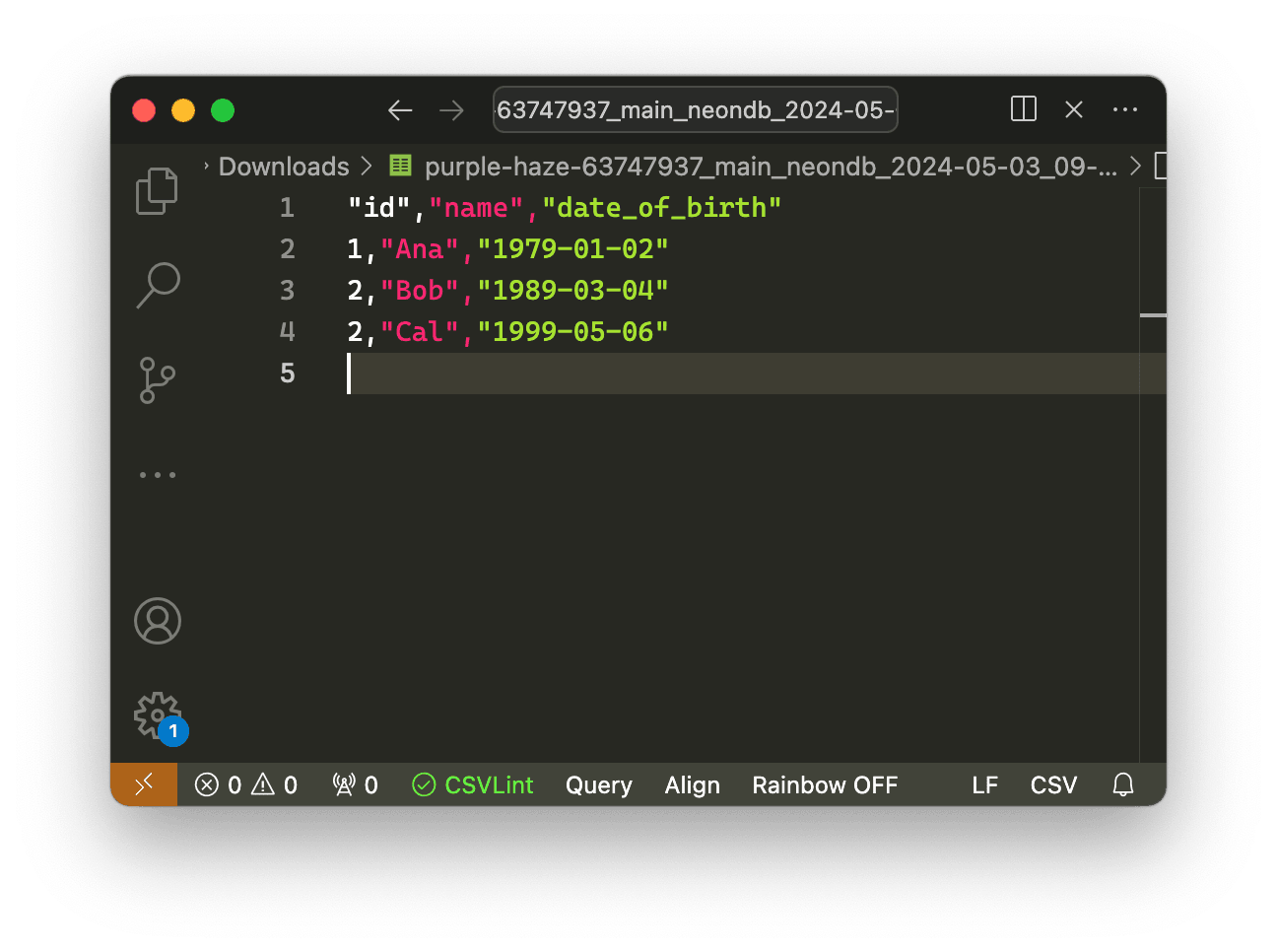
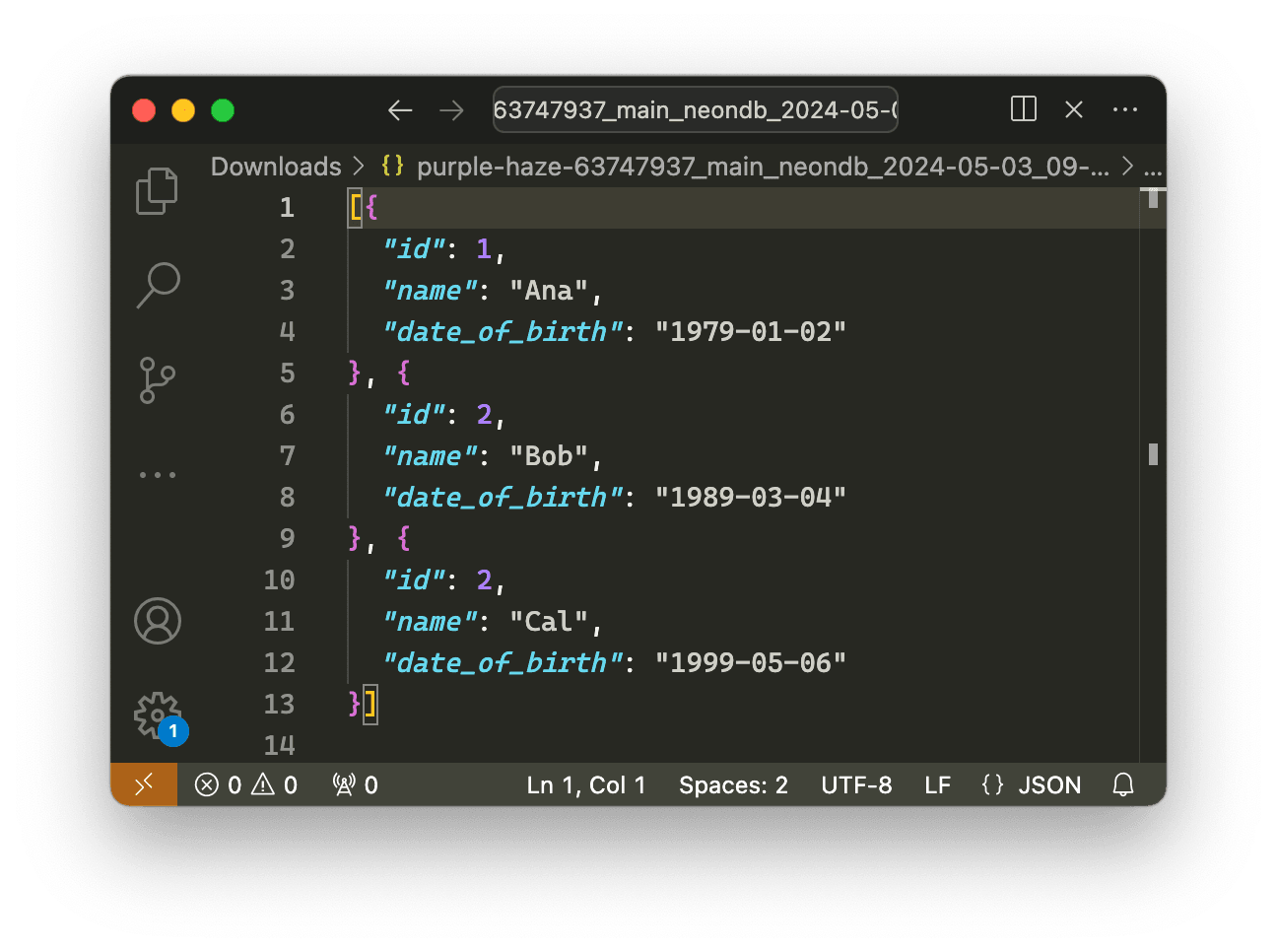
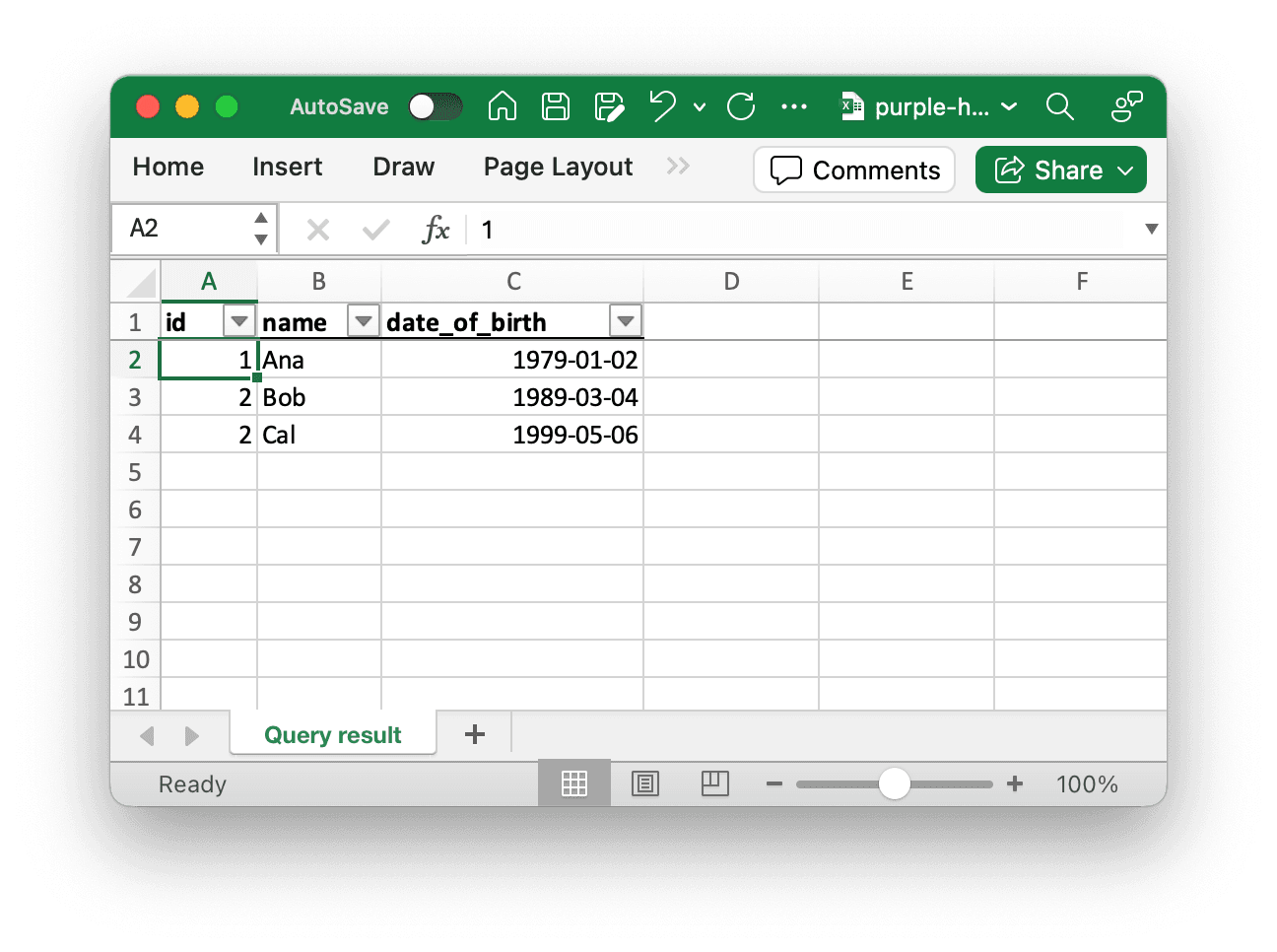
In the rest of this post I set out what I learned in implementing this feature. I also introduce a couple of new npm packages that could help anyone working on similar tasks.
CSV + JSON
There were no big surprises implementing CSV and JSON download. The key thing to ensure for both formats was that very big or precise numbers (Postgres int8s and decimals) didn’t at any point get parsed to JavaScript numbers, because that would cause precision to be lost.
The other tiny wrinkle was ensuring that there are no duplicate JSON object keys even when multiple result columns have the same name.
Excel’s XML
Providing an .xlsx download is slightly less straightforward. Modern Office documents consist of a set of XML files combined into an ordinary .zip archive. So: first we need to create some XML files in the right format. And then we need to zip them up.
There are, of course, libraries on npm that can do this for us. But the ones I found were either so basic that they didn’t do what I needed, or so complex that they would add a lot of weight to the Neon console’s bundled JavaScript. And anyway, doing it yourself is fun, educational, and free of worries about what npm horrors have been imported in dependencies many levels deep. 😀
Excel’s XML documents turn out to be moderately comprehensible. There are, much as you might expect, <row> elements that contain <c> (cell) elements that contain <v> (value) elements, and so on. Much of this can be figured out simply by unzipping a simple .xlsx file, but there are also useful references online.
There were only a couple of wrong turns:
- I thought I knew that dates and times in Excel were represented as days since 1 January 1900, so I was surprised when the dates in my initial
.xlsxfiles were off by exactly two days. The first problem was that dates in Excel are actually represented as days since 0 January 1900 (you and I might call that 31 December 1899, but Excel doesn’t: try entering zero in an Excel cell, then changing its display to a date format).
The second problem was Excel’s 1900-is-a-leap-year bug, which causes an off-by-one error for any date after 28 February 1900. The bug originated as a compatibility measure with Lotus 1-2-3. After bumping into it myself, I remembered first hearing about it in a classic Joel on Software post. - I’d assumed that Excel column references were just numbers in base 26, using letters of the alphabet. If that were the case, A would represent zero and B would represent one, so the column after Z would be BA. But in Excel, the column after Z is AA. In decimal terms, it’s as if the number after 9 was 00. So this needed a little bit more thought.
Client-side Zip
With these issues fixed, I turned to zipping (and unzipping). First, note that if you’re ever tinkering with an .xlsx file — unzipping, modifying, and re-zipping it — you may encounter these small but briefly head-scratching obstacles:
- At zip time, the order of files in the
.ziparchive matters. In particular, a file called[Content_Types].xmlhas to be first, which means that manually zipping the right files in one go doesn’t always work. Instead, usezipat the command line to zip[Content_Types].xml, then use it again to add the other files. - At unzip time, Archive Utility on the Mac flatly refuses to unzip an
.xlsxfile that has been renamed to.zip. “Unable to expand ‘workbook.zip’. It is in an unsupported format”, it says. This is either very clever or very stupid (is it usingfileto detect the file type?). But again, it’s no big problem to use the command-lineunziptool or The Unarchiver on a Mac instead.
When it comes to creating Zip archives in the browser, I was pleased to find that, since around a year ago, all the major browsers (plus Node and Deno, but not yet Bun) support the Compression Streams API. The CompressionStream interface to this can return either raw DEFLATE data, or ZLIB or GZIP data. The latter two include some metadata and a CRC.
A little disappointingly, none of these formats is quite the same as you find in a Zip (originally PKZIP) archive. But the two key computationally-intensive components of each file inside a Zip archive — the compressed data plus the CRC — turn out to be identical to those used by GZIP.
That means we can write a very small, very fast Zip library that works in all modern browsers (as well as Node and Deno). All it has to do is to rearrange the binary output of a GZIP CompressionStream alongside a few other bit of metadata, and — hey presto! — you can generate .zip, .xlsx, .apk and others in less than 2KB (zipped, of course) of code.
Open source
I’ve released this Zip library under the name littlezipper: find it on npm and on GitHub.
I’ve also released the Excel worksheet-writing library that depends on it, and that powers Neon’s Excel downloads: this one is called xlsxtable. Again, you’ll find it on npm and on GitHub.
As ever, if you have any feedback on any of these new features, please let us know on Discord.